






Suyash Bagad
Cryptography Engineer
Aztec Study Club - Session 9
11th May 2022
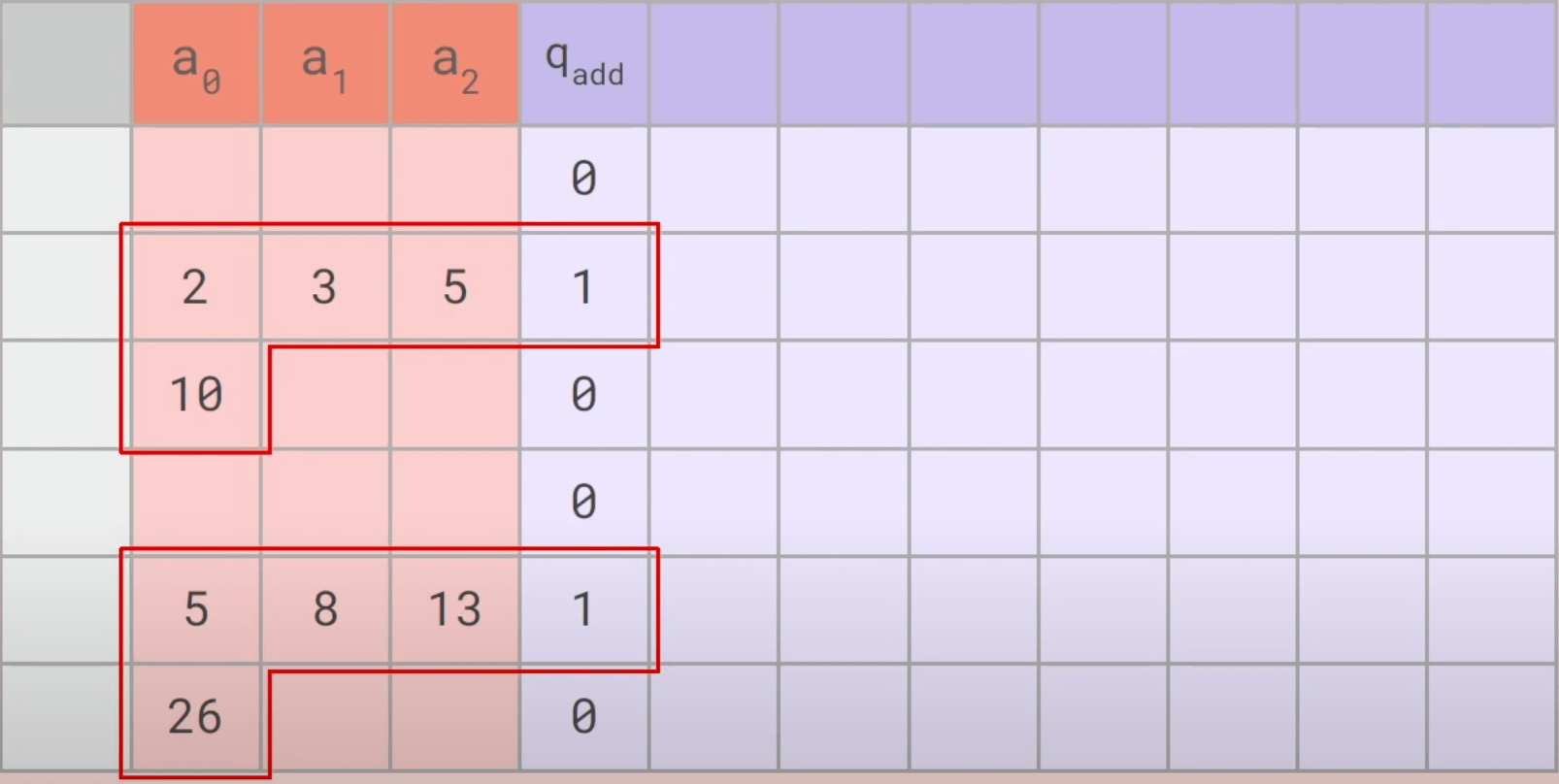
StandardPlonk
TurboPlonk
Width = \(4\)
Circuit size = \(n\)
Copy constraints
Cell-wise permutation
Width = \(4\)
Circuit size = \(n\)
\(x\)
\(y\)
\(1\)
\(\omega\)
\(\omega^2\)
\(\omega^4\)
\(\omega^5\)
\(\omega^6\)
\(\omega^7\)
\(\omega^3\)
Width = \(4\)
Circuit size = \(n\)
Width = \(4\)
Circuit size = \(n\)
Width = \(4\)
Circuit size = \(n\)
Width = \(6\)
Circuit size = \(n\)
Width = \(6\)
Circuit size = \(n' < n\)
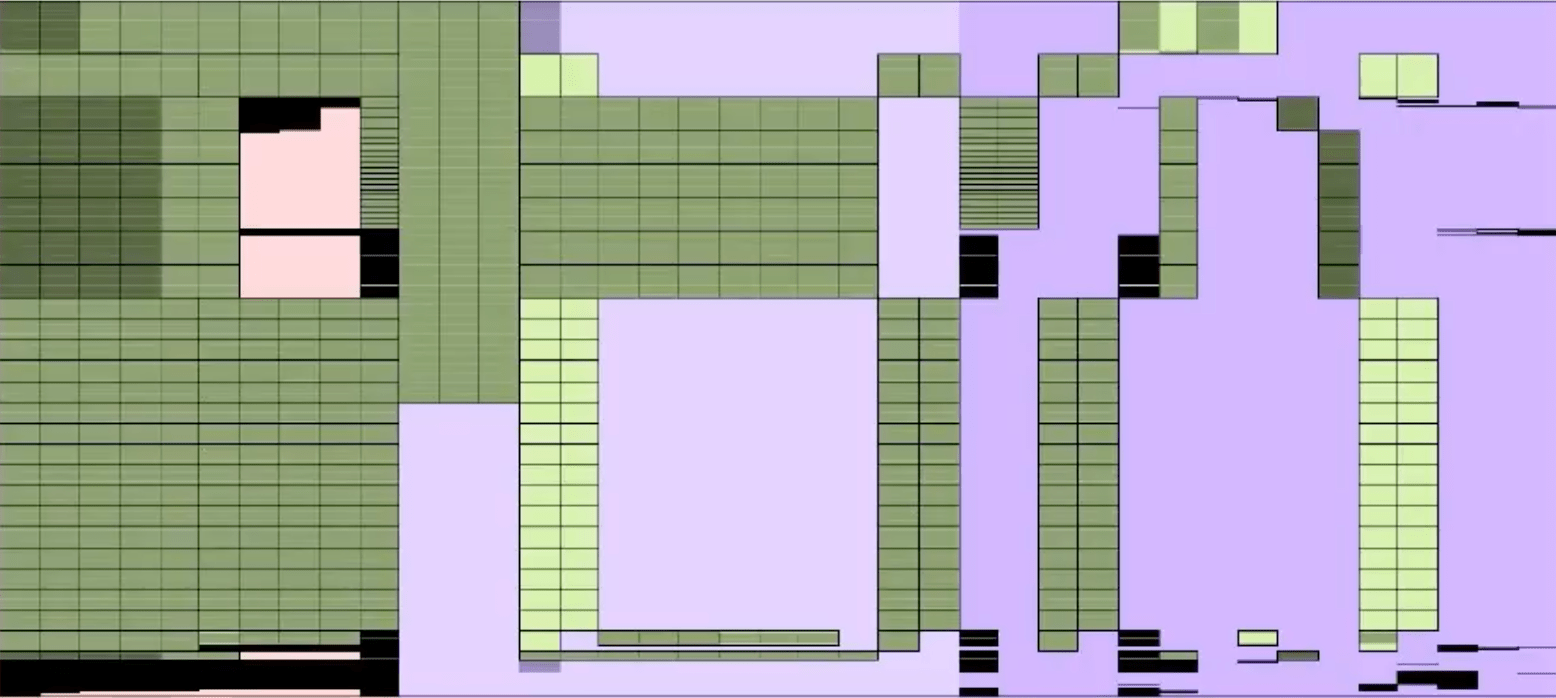
Credit: ZK7: Latest developments in Halo2 by Ying Tong Lai 🔗
empty wire values
Credit: ZK7: Latest developments in Halo2 by Ying Tong Lai 🔗
empty spaces
width \(= 2^{12}\)
width \(= 2^{11}\)
Credit: ZK7: Latest developments in Halo2 by Ying Tong Lai 🔗
TurboPlonk for scaling on Ethereum
TurboPlonk + FRI for scaling on Ethereum
UltraPlonk + recursion to build a 5kb blockchain
UltraPlonk + Bulletproofs = Halo2
UltraPlonk (they call is PlonkUp) for RegDeFi (?)
Optimized Poseidon using TurboPlonk for zkRollup on Tezos
By Suyash Bagad
Some useful ideas for optimising plonk (by Aztec and other teams).



